


Multiple Source Aggregation Model
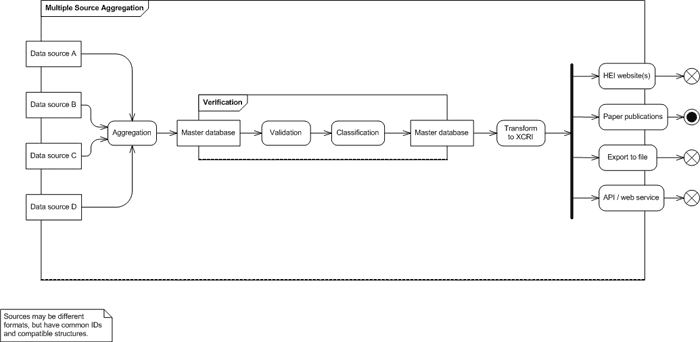
FIGURE 10: UML ACTIVITY DIAGRAM FOR MULTIPLE SOURCE AGGREGATION MODEL
Typified by
Characteristic |
Description |
| Number of courses | Large number of courses |
| Complexity of provision | Complex provision |
| Number of sources | Many authoritative sources, with different formats, for example databases for marketing, admissions, MIS, Word documents. |
| Quality of authoring | Good quality authoring |
| Data structures | Moderately well defined data structures; some anomalies in sources can be handled via transformations and normalisation |
| Update frequency | Annual for preference, but for some data sets higher frequency can be accomplished. |
| Audit trail | Audit trail information varies dependent upon source. Standardisation of the method for indicating updated records on the master database is important, so that updated records can be indicated in XCRI and thereby identified by data aggregators. |
| Centralisation | Partially centralised, for example undergraduate courses information may be completely centralised for ease of updating of UCAS information, but postgraduate and short courses may be de-centralised. As many authoritative sources as possible are centralised in the master database. |
| Process capability | Primarily a managed process leading into the master database; some feeds may be ad hoc. Managed and improving process required for the flow between the master database and final outputs. |
| Technical capability | High technical capability |
| Organisational context | Good organisational context; co-operation from owners of the data sources is required |
| Resources | Significant resources required for creation and management of the master database, aggregation and creation of outputs. |
TABLE 4: CHARACTERISTICS OF THE MULTIPLE SOURCE AGGREGATION MODEL
Description of scenario
The HEI has a large number of courses, whose data is held in a variety of databases, Word documents and spreadsheets. Information managers in the HEI have been thinking about consolidating their course advertising information for a while, and some preliminary steps have been taken. The most significant of these are:
- The most important sources of course advertising information have been identified;
- Agreement has been reached with senior management for the provision of resources, and with data owners to provide the information to a central source;
- A common identifier is now used across all the sources, although two or three of them require further work, so that course instances (presentations) can be used to generate full course records;
- The descriptive text on the website has been analysed and slightly re-structured, so that the XCRI recommended course description vocabulary can be used;
- Venue information (particularly names and addresses) has been standardised across all sources.
The implementation of XCRI was handled through a series of discrete projects over a period of 3 years. It was decided early on that no attempt would be made to satisfy all the functional requirements for courses information, but that the focus would be on course advertising information only, with a concentration on outputs to supply the HEI’s website, paper publications and an XCRI web service. The last would be available to internal and external organisations as the HEI’s authoritative source of course advertising information.
The development of a feed from each data source into the master database was handled as a separate project within an overall service oriented approach, co-ordinated through a central office. Technical teams shared expertise by holding regular informal and formal workshops.
The development of the master database was a key project. It was built using XCRI-CAP structures, and also included a range of structural and vocabulary services for internal and external use (for example its reference data included the latest UCAS entry requirement and subject vocabularies and data structures).
The scenario does not represent a fully centralised approach to all courses information. Information relating to curriculum management and MIS systems is still held in separate systems. However, system architects have made sure that a common approach to identifiers is used, and that each system has the potential to link to others, enabling system integration at a later date.
Example: Manchester Metropolitan University
Extract from the report of the project:
1.4 Challenges and Solutions for Definitive Course Information at MMU
MMU is a large and diverse institution. Information about courses is generated, updated and consumed by varied institutional stakeholders. New courses are proposed to the Centre for Academic Standards & Quality Enhancement. Once approval in principle is obtained for running the course, the External Relations department will be alerted so that it can be advertised "subject to full approval". An early entry will be made at this time in an Access database maintained within the External Relations department, which is used to populate the online prospectus and to produce the printed version. Full documentation will be produced in Microsoft Word describing the rationale, academic and resource dimensions of the course and its constituent units, which will be considered by a validation panel at an event held to scrutinise the course. When the course has been validated, the External Relations department will be informed and the course will be entered into the student records system so that it can receive applications and enrolments.
When the project started, there was no common key between the Access Database of courses used for advertising, the documentation approved in validation and modification events, and the curriculum objects to which students applied and were enrolled in the student records system. Items could be matched by human intervention as, for instance, course leaders were aware of descriptions they had provided to marketing colleagues and could search by title on the web prospectus to confirm the descriptions were being used; they had copies of the documentation they had written for validation events; and knew how to look up applications and enrolment data for 'their' courses in the student records system. For undergraduate courses, UCAS codes helped the process of matching marketing, quality and enrolment representations of a course. For postgraduate and short courses, things were more challenging, which poses particular problems for aggregators such as the Greater Manchester Strategic Alliance.
MMU's solution to this problem of islands of course information is to launch an Academic Database project that will deliver a definitive curriculum database together with the workflow routines to ensure that it is maintained by the right people in ways that adhere to quality requirements for scrutiny and audit trails. The mini project has served to demonstrate the need for the Academic Database project, and the critical importance of common identifiers for aggregating data gathered for different purposes.
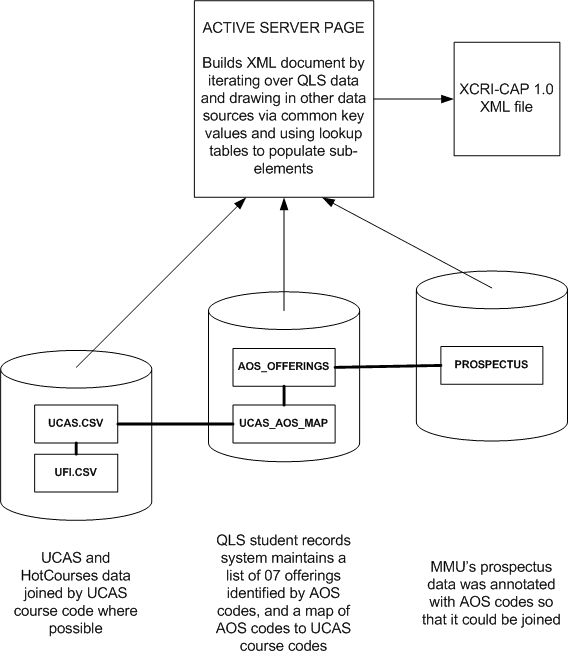
FIGURE 11: INTERIM SOLUTION PRIOR TO ACADEMIC DATABASE PROJECT
